ursadb
Index types
TL;DR: Use [gram3, text4, wide8, hash4] by default,
[gram3, text4, wide8] if you want to save disk space.
Every dataset consists of one or more indexes. All indexes contain the same files, but represent them in different ways to speed up different kinds of searches. Currently there are four types implemented:
gram3- classic trigramstext4- behave like 4grams for text, but can’t query anything elsewide8- behave like 4grams for utf16 ascii text, but can’t query anything elsehash4- 4grams packed into three bytes (with collisions)
More indexes means more accurate results, but indexing will take longer, and more disk will be used.
gram3is the most basic and important index, it should be used in all situations.text4andwide8indexes are very useful for textual data. They don’t need a lot of space and improve results significantly, so they are almost always a good idea.hash4is the most complicated type. It’s not strictly necessary, and ursadb will work without it smoothly. But if you have enough disk space and can afford extra processing time, it’ll reduce the number of false positives (and, in turn, make ursadb faster).
Details
gram3 index
UrsaDB is using few slightly different methods of indexing files, gram3 index
is the simplest one.
When the database is about to create a gram3 index for a given file, it extracts all possible three-byte combinations from it. An index is a big map of: 3gram => list of files which contain it.
For instance, if we would index a text file containing ASCII string TEST MALWARE (ASCII: 54 45 53 54 20 4D 41 4C 57 41 52 45), then the database would generate the following trigrams (_ denotes space character):
| # | Substring | Trigram |
|---|---|---|
| 0 | TES |
544553 |
| 1 | EST |
455354 |
| 2 | ST_ |
535420 |
| 3 | T_M |
54204D |
| 4 | _MA |
204D61 |
| 5 | MAL |
4D616C |
| 6 | ALW |
414C57 |
| 7 | LWA |
4C5741 |
| 8 | WAR |
574152 |
| 9 | ARE |
415245 |
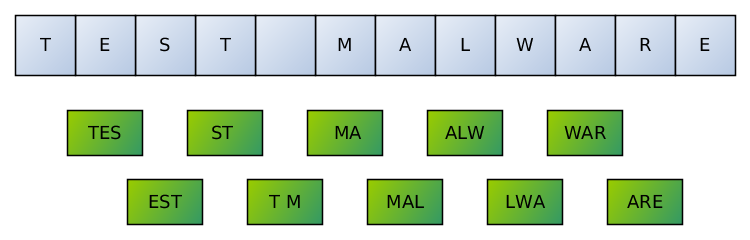
An index maps a trigram to a list of files, so the new file will be added to the abovementioned lookups.
gram3 queries
When querying for string TEST MALWARE, the database will query trigram index in order to determine which files do contain sequence 544553, then which files contain 455354 and so on till 415245. Such partial results will be ANDed and then the result set (list of probably matching files) is returned.
The drawing presents how trigrams are mapped to file contents.
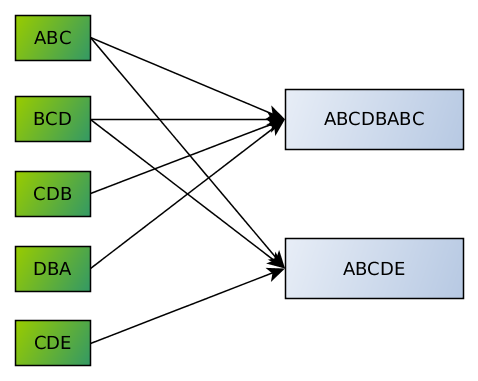
Such searching technique sometimes may yield false positives, but it’s never going to yield any false negatives. Thus, it may be appropriate for quick filtering (see mquery project - we use UrsaDB there in order to accelerate the process of malware searching).
text4 index
String literals are very common in binaries. Thus, it’s useful to have a specialized index for ASCII characters.
In text4 index, ASCII characters are packed in a manner similar to base64 algorithm. Due to that, it is possible to generate a trigram out of four characters.

Note that such an index doesn’t respond to queries containing non-ASCII bytes, so it should be combined with at least gram3 index.
wide8
Because searching for UTF-16 is also useful, there is a special index which works similarily to text4. In this case, ASCII characters interleaved with zeros are decoded.

hash4
Finally, there is hash4, which creates trigrams based on hashes of 4-byte sequences in the source file. This makes it possible to cheat and get some of the benefits
of 4grams using only 3grams under the hood.
disk usage
Some statistics. I’ve downloaded vx-underground malware packs (3.36M files, 634 GB). I also deleted files larger than 5MB to save some disk space (wasn’t worth it). Final collection size: 3.28M files, 617 GB.
For this dataset, combined sizes of all indexes is:
| index type | index size | index / data% |
|---|---|---|
| gram3 | 421 GiB | 68.23% |
| text4 | 17 GiB | 2.75% |
| wide8 | 4 GiB | 0.64% |
| hash4 | 450 GiB | 72.93% |