Yara support
Introduction
YARA is pretty fast by itself, but it needs to read every file and it takes a long time for large collections. To speed up this process, we pre-filter the results, so it is only necessary to run YARA against a small fraction of binaries:
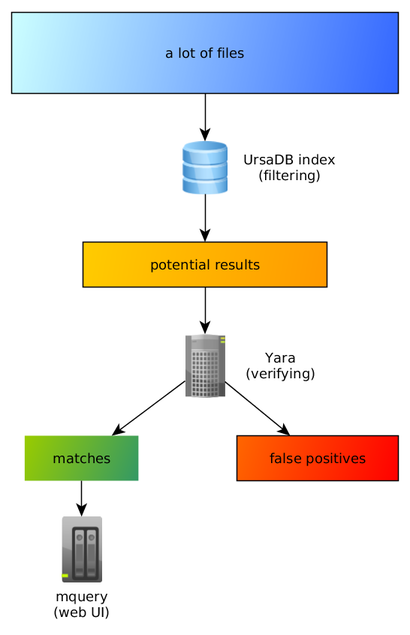
Internally this is implemented with an n-gram database called Ursadb. Visit ursadb’s repository for more details.
In short, we look for short (3-4) byte fragments in indexed files, and we can tell (almost) immediately which files contain the given 3-byte pattern. For example for the following rule:
rule example
{
strings:
$test = "abcd"
condition:
$test
}
Mquery will run yara only on files that have both “abc” and “bcd” substrings, instead of running it on every file in the dataset.
Known limitations and design decisions.
Mquery’s goal is to accelerate Yara queries. It should always return the same results as running Yara on the dataset naively. If it doesn’t, please report a bug.
Because of the specifics of the database engine, we only accelerate a pretty naive subset of Yara. Additionaly, false positives are possible during the filtering stage. Thus, we still have to re-check all the potential results with the original Yara binary.
Parsing Yara rules is possible thanks to the highly recommended yaramod library by Avast.
The following examples will give you a rough idea of what works and what is not, due to the accelerator limitations:
- Counting strings:
rule CountExample
{
strings:
$a = "dummy1"
$b = "dummy2"
condition:
#a == 6 and #b > 10
}
The rule is parsed to ("dummy1" AND "dummy2"). Counting occurrences is done by Yara at
the later stage.
atconstruct:
rule AtExample
{
strings:
$a = "dummy1"
$b = "dummy2"
condition:
$a at 100 and $b at 200
}
The rule is parsed to ("dummy1" AND "dummy2"). Verifying the location is done by Yara
at the later stage.
inconstruct:
rule InExample
{
strings:
$a = "dummy1"
$b = "dummy2"
condition:
$a in (0..100) and $b in (100..filesize)
}
The rule is parsed to ("dummy1" AND "dummy2"). Again, further verification
will be done by Yara in the second stage.
- Variables:
rule FileSizeExample
{
condition:
filesize > 200KB
}
This is parsed to (). We don’t accelerate file size queries, so
all the files will have to be scanned with Yara rule.
Similarly, we can’t speed up other expressions like:
rule IsPE
{
condition:
// MZ signature at offset 0 and ...
uint16(0) == 0x5A4D and
uint32(uint32(0x3C)) == 0x00004550
}
In general, everything that doesn’t have an explicit string will not get accelerated. This is by design - speeding up arbitrary complex expressions is out of scope (and probably impossible).
x of yconstruct
This will work as you could expect:
rule OfExample1
{
strings:
$a = "dummy1"
$b = "dummy2"
$c = "dummy3"
condition:
2 of ($a,$b,$c)
}
- Multiple rules.
rule Rule1
{
strings:
$a = "dummy1"
condition:
$a
}
rule Rule2
{
strings:
$a = "dummy2"
condition:
$a and Rule1
}
This is supported and parsed to ("dummy1" AND "dummy2").
Efficient Yara rules.
If you’ve read the previous two paragraphs, you probably have a rough idea of what will work and what won’t.
Long strings are where mquery really shines. Let’s take the following Emotet rule as an example:
rule emotet4_basic
{
meta:
author = "cert.pl"
strings:
$emotet4_rsa_public = {
8d ?? ?? 5? 8d ?? ?? 5? 6a 00 68 00 80 00 00 ff 35 [4] ff
35 [4] 6a 13 68 01 00 01 00 ff 15 [4] 85
}
$emotet4_cnc_list = { 39 ?? ?5 [4] 0f 44 ?? (FF | A3)}
condition:
all of them
}
This is parsed to the following expression:
min 2 of ({8D} & {8D} & {6A006800800000FF35} & {FF35} & {6A136801000100FF15} & {85}, {39} & {0F44})
Strings shorter than 3 characters are ignored by all the index types, so this is further simplified to:
min 2 of ({6A006800800000FF35} & {6A136801000100FF15}, ())
And this is equivalent to:
{6A006800800000FF35} & {6A136801000100FF15}
And yet this is usually pretty fast to query. But few more question marks in the rule could cripple mquery performance.
Remember that parser is your friend. If your query runs too slow, click “parse” instead of “query” and investigate if the query looks reasonable.
Slow Yara rules.
Some yara rules cannot be optimised by mquery and will end up scanning the whole malware collection. One example of such rule is:
rule UnluckyExample
{
strings:
$code = {48 8b 0? 0f b6 c? 48 8b 4? 34 50}
condition:
all of them and pe.imphash() == "b8bb385806b89680e13fc0cf24f4431e"
}
This is not necessarily a bad rule, but it will generate a following ursadb query:
{}
In other words, we ask for every file in the malware collection. That’s because there’s not a single full 3gram that can
be used to narrow the set of suspected files. Due to how mquery works, this will
cause a yara scan of every file in the dataset, and will be usually very slow. Becaue of this,
such queries are disallowed by default. They can be enabled by setting
query_allow_slow config key to true. In this case mquery will allow such
queries, but it’ll ask for confirmation first.
Caveats and advanced topics
Mquery ignores alternatives in hex strings:
rule hex_alternatives {
strings:
$test2 = { ( 11 11 11 | 22 22 22 ) 33 33 33 }
condition:
all of them
}
Everything in the brackets will be ignored, and this is equivalent to just { 33 33 33 }. Handling this correctly is non-trivial, and tests on a real-world yara rule collection have shown that in most cases it’s impossible for mquery to optimize alternatives in hex string anyway.