Plugins
Plugins can be used to extend mquery in organisation-specific ways.
There are two types of plugins:
filter plugins- run before yara matching, can discard filesmetadata plugins- run after yara matching, can add additional metadata
Configuration
Visit the /config endpoint to change configuration variables required
by plugins.
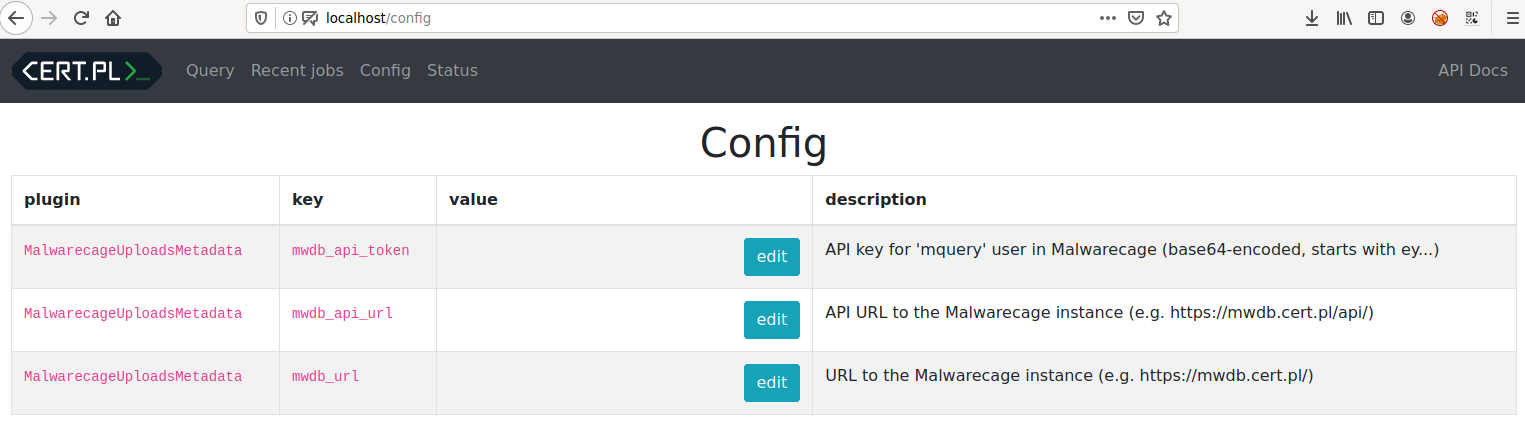
To add a new plugin to the system, you need to change mquery.plugins key in the config. For example:
[mquery]
plugins=plugins.mwdb_uploads:MalwarecageUploadsMetadata
To load a plugin MalwarecageUploadsMetadata from plugins.mwdb_uploads
module.
Remember that you can also use environment variable MQUERY_PLUGINS to do the same thing - this may be useful for docker-based deployments.
Filter plugins
Filter plugins can be used to discard files quickly (before even running yara rules), or to process paths returned from Ursadb.
The very simple example of a filter plugin is RegexBlacklistPlugin
- plugin that rejects all files matching provided regex:
class RegexBlacklistPlugin(MetadataPlugin):
is_filter = True
config_fields = {
"blacklist_pattern": "Regular expression for files that should be ignored",
}
def __init__(self, db: Database, config: MetadataPluginConfig) -> None:
super().__init__(db, config)
self.blacklist_pattern = config["blacklist_pattern"]
def filter(self, orig_name: str, file_path: str) -> Optional[str]:
if re.search(self.blacklist_pattern, orig_name):
return None
return file_path
When the filter method returns None, it means that checked file should
be discarded. This plugin can be configured using the /config endpoint.
This API allows filter plugins to change the returned file path, which can be
useful for more advanced uses of the filter plugin. For example,
GzipPlugin
which extracts contents of files ending with .gz (so that yara is run on the
uncompressed contents):
class GzipPlugin(MetadataPlugin):
is_filter = True
def __init__(self, db: Database, config: MetadataPluginConfig) -> None:
super().__init__(db, config)
self.tmpfiles: List[IO[bytes]] = []
def filter(self, orig_name: str, file_path: str) -> Optional[str]:
tmp = tempfile.NamedTemporaryFile()
self.tmpfiles.append(tmp)
if orig_name.endswith(".gz"):
with gzip.open(file_path, "rb") as f_in:
with open(tmp.name, "wb") as f_out:
shutil.copyfileobj(f_in, f_out)
return tmp.name
return file_path
def clean(self):
for tmp in self.tmpfiles:
tmp.close()
self.tmpfiles = []
The same method can be used to, for example, automatically download and extract files from s3 automatically.
Filter plugins are ran before yara matching, and before file downloads. To avoid unexpected behaviour, the same set of plugins should be active in the web UI and in the daemon.
Warning: if you have multiple backends either ensure that all backends and the web frontend use the same set of plugins, or be very careful about how they interact.
For example, imagine that of the backends does gzip decompression and the other doesn’t. Without any filter plugins installed on the frontend, download results will contain a mix of compressed and uncompressed files. Right now the answer to this is to write a plugin that does conditional decompression depending on which backend a file came from. It’s not handled automatically.
Metadata plugins
Metadata plugins are used to enrich results with additional metadata.
For example, we use them to display mwdb tags in
mquery. They can also be used as post processing hooks, for example to
report all matched files to some other system. This can be used to integrate
systems with each other (for example, we plan to use it to add mquery
matches to mwdb.
The very simple and probably useless metadata plugin is ExampleTagPlugin:
class ExampleTagPlugin(MetadataPlugin):
cacheable = True
config_fields = {
"tag": "Everything will be tagged using that tag",
"tag_url": "Tag URL e.g. http://google.com?q={tag}",
}
def __init__(self, db: Database, config: MetadataPluginConfig) -> None:
super().__init__(db, config)
self.tag = config["tag"]
self.tag_url = config["tag_url"]
def extract(
self, identifier: str, matched_fname: str, current_meta: Metadata
) -> Metadata:
return {
"example_tag": {
"display_text": self.tag,
"url": self.tag_url,
}
}